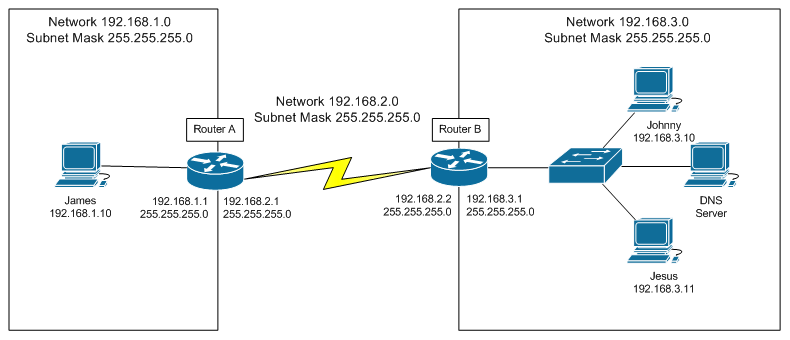
With regard to static routing, consider the above diagram. We have three separate networks: 192.168.1.0, 192.168.2.0, and 192.168.3.0. At first, network hosts (routers, computers, etc.) can only communicate with other hosts that are on their own network. For instance, the computer named James has a single interface on network 192.168.1.0, so that’s the only network that it can ‘see’. Initially, it will only be able to communicate with Router A.
Router A has network interfaces on the 192.168.1.0 and 192.168.2.0 networks, so those are the two networks that it can ‘see’. These are the only networks Router A ‘knows’ about, so it can only communicate with hosts on the 192.168.1.0 and 192.168.2.0 networks. So Router A doesn’t even ‘know’ that the 192.168.3.0 network exists.
Similarly, Router B can ‘see’ networks 192.168.2.0 and 192.168.3.0. When you enter a route into the table, you’re telling a host that there’s a new network it can get to, and you’re giving it the address of a gateway that it can use to get to the new network.
So to be able to contact Jesus (or any other host on the 192.168.3.0 network) from Router A, you’d enter the command:
ip route 192.168.3.0 255.255.255.0 192.168.2.2
^ ^ ^
network mask gateway
This works because Router B can ‘see’ both Router A and Jesus. Thanks to this routing table entry when Router A wants to reach the 192.168.3.0 network, it knows it can get there via Router B at 192.168.2.2, so it sends the packet to Router B. Router B can see the 192.168.3.0 network directly, so it forwards the packet along to Jesus at 192.168.3.11.
So, now we know how to direct router A to the 192.168.3.0 network. But what if we want James to also be able to reach the 192.168.3.0 network? Well, Router A already knows how to get there, and James can already ‘see’ Router A, since they’re both on network 192.168.1.0. So we can just tell James to use Router A as its gateway to the 192.168.3.0 network. If James were a router instead of a computer, we’d use the command:
ip route 192.168.3.0 255.255.255.0 192.168.1.1
^ ^ ^
network mask gateway
James would then be able to contact Jesus (or any host on the 192.168.3.0) network by forwarding the packet to 192.168.1.1 (Router A), which would then forward the packet to 192.168.2.2 (Router B) which would then forward the packet to its destination (Jesus in this case) via its directly connected interface.
Now, for Jesus to be able to respond to James, Jesus would need to have Router B set up as its gateway to the 192.168.1.0 network, and Router B would have to have Router A set up as its gateway to the 192.168.1.0 network. Then, any host on the 192.168.1.0 network would have a path to the 192.168.3.0 network and vice versa.
(reference: https://serverfault.com/questions/171551/help-me-understand-the-ip-route-command-for-cisco-routers )